
I am delighted to announce that our research paper, “From Untamed Black Box to Interpretable Pedagogical Orchestration: The Ensemble of Specialized LLMs for Adaptive Tutoring,” has been formally accepted for presentation at AIED 2026 (The International Conference on Artificial Intelligence in Education).
This acceptance is a milestone on my doctoral journey, which began in September 2025 at the Singapore University of Technology and Design (SUTD). It marks the crucial transition of concepts from theoretical pedagogy into technically validated, scalable AI architectures.
The Academic Context: Closing the Gap in “Machine Pedagogical Intelligence”
When I published my recent book, “Machine Pedagogical Intelligence” (MPI) in late 2025, the central argument was clear: Intelligence in education is not just about raw cognitive power (e.g., GPT-5 or Llama 3). It is about pedagogical discipline.
Current AI tutoring models suffer from what I defined in the book as The Mastery Gain Paradox. Monolithic, general-purpose LLMs are designed to be “helpful.” In an educational context, this results in “frictionless satisfaction”—the AI provides the student with the correct answer too quickly to keep them happy. This phenomenon masks stagnation; the student feels like they are progressing, but their actual latent mastery of the subject remains low.
Joining SUTD allowed me to focus purely on the technical validation required to solve this paradox. We needed to move from theorizing MPI to engineering it.
Introducing the ES-LLMs Architecture: A Team of Specialized LLMs
The paper we are presenting at AIED 2026 provides the technical solution: the Ensemble of Specialized LLMs (ES-LLMs).

The fundamental shift this architecture introduces is decoupling deterministic pedagogical logic from natural language generation. We are moving away from the “Stochastic” (unpredictable, monolithic) model and toward a “Deterministic” (rule-governed) framework.
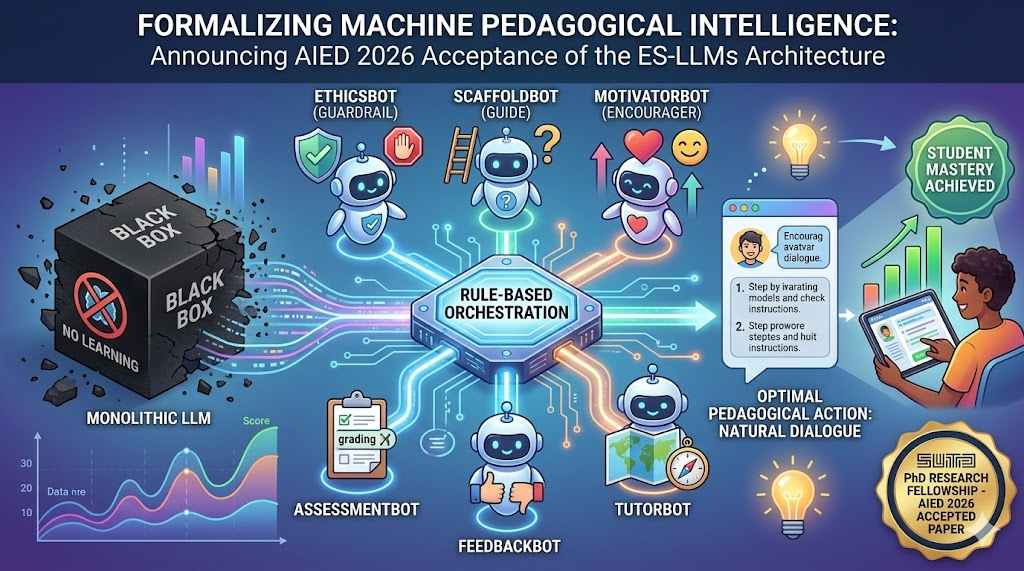
We achieved this by building a “Team of Specialists,” replacing a single black-box model. Here is the structure outlined in our accepted paper (and visualized in the infographic below):
The Components of the Ensemble
Our system does not just react to student prompts; it models the student using historical data (BKT Mastery Posteriors) and real-time sentiment (Affect Signals) before deciding how to act. These inputs feed into the heart of the system:
- Rule-Based Orchestration (The Brain): We utilize a Subsumption Architecture, a concept derived from robotics. This ensures that pedagogical rules explicitly override the LLM’s natural generative tendencies. The system prioritizes Safety (EthicsBot) > Assessment > Pedagogy (Scaffolding/Motivation). This makes the system’s decision-making fully interpretable.
- Specialized Bots (The Subject Matter Experts): These are light, fine-tuned models that handle specific pedagogical functions:
- 🛡️ EthicsBot: A dedicated “guardrail” that enforces constraints, such as the crucial “attempt-before-hint” rule, preventing students from “gaming” the system for easy answers.
- 🪜 ScaffoldBot: The specialized “Guide” that determines the optimal depth of hints (Minimal, Medium, Full) based on historical error patterns.
- ❤️ MotivatorBot: The “Encourager” designed specifically to detect frustration and provide affective support.
This structure allows the system to determine the “Optimal Pedagogical Action.” Only after this calculation is complete is the final LLM—the Renderer—invoked to synthesize the final dialogue.
The Proven Results: Validation of Pedagogical Discipline
The power of this architecture isn’t just theoretical; it has been rigorously validated in simulations against standard monolithic baselines. The results, highlighted in the infographic, confirm our hypothesis:
- 100% Constraint Adherence: In 2,400 simulations, the ES-LLMs architecture never violated instructional constraints. This is the bedrock of trusted AI tutoring.
- 3.3x Increase in Hint Efficiency: By delivering hints only when the student needs them (Scaffolding), we achieve significantly higher mastery gain per interaction.
- 54% Reduction in Token Costs: By making specialized decisions using smaller models and invoking the primary LLM only for final rendering, the system is dramatically cheaper at scale.
- Improved Performance: We recorded an average latency of 625ms (vs. 800ms) and a human preference rating of 91.7% (vs. 6.9%).
Conclusion: From Singapore to AIED 2026
This work demonstrates that “Machine Pedagogical Intelligence” is achievable by applying engineering discipline to large language models. The SUTD doctoral fellowship has provided the ideal ecosystem—fostering technical innovation while honoring the complex science of learning.
We are excited to share this breakthrough with the AI in Education community in 2026 and look forward to the subsequent discussion on how orchestrated architectures can redefine personalized tutoring.
You can read the full pre-print and explore the architecture here: https://doi.org/10.48550/arXiv.2603.23990